每天都有成千上万的人通过Google来搜索信息,从旅途需要花费多长时间到怎样治疗他们孩子的病,各式各样的信息都有,这无疑极大的方便了人们的生活。
这一系列的搜索数据也从侧面显示出了搜索这些信息的人本身的情况,比如他们的想法、需求、忧虑等非常有价值的信息。如果这些信息的搜索可以准确的反映出人们的生存情况,那么分析人员就有可能利用这些信息追踪疾病情况,预测新商品的销售情况,甚至预测选举的结果。
2008年,谷歌的研究人员探索了其中的可能性,并宣称他们能够根据人们在搜索引擎上留下的信息对流感进行“即时预报”。研究人员在《自然》杂志上撰文表示,能够进行这种预测的关键在于一旦人们患上了流感,就会在谷歌中搜索很多关于流感的相关信息,这就可以形成有关于流感流行情况的整体性趋势信号。该文章还表示,如果把谷歌搜索引擎上的相关信息与美国疾病预防控制中心(Centers for Disease Control and Prevention,CDC)的流感监测信息进行调整对比,就可以提供更为精准的流感趋势预测,这不仅把人们在搜索引擎上留下的“垃圾”变成了拯救生命的“启示”,并比当前CDC的数据预测预测提早至少2周。
这一切听起来都很有道理,然而理想很丰满,现实很骨感。谷歌流感趋势(Google Flu Trends,GFT)最终还是失败了,而且失败得彻彻底底:相比于2013年实际的流感趋势,GFT的预测偏差高达140%。当谷歌黯然关闭GFT的时候,这个项目已经从“大数据运用的典范”变成了“大数据的缺陷的典范”。
但GFT的失败并不能够抹灭大数据本身的价值。相反,这个项目很好的凸显出了很多大数据应用实践中的问题,也就是我们所说的“大数据的傲慢”。
“大数据傲慢”指的是这样一种观点:即认为大数据可以完全取代传统的数据收集方法,而非作为后者的补充。这种观点的最大问题在于,绝大多数大数据与经过严谨科学试验得到的数据之间存在很大的不同。
编写一个将5000万搜索关键词与1152个数据点相匹配的算法是非常困难的,很有可能会出现过度拟合(将噪声误认为信号)的情况:很多关键词只是看似与流感相关,但实际上却并无关联。事实上,在2013年的报道之前,GFT就多次在很长一段时间内过高地估计了流感的流行情况。 2010年的一项研究发现,使用CDC的滞后预测报告(通常滞后两周)来预测当前的流感疫情,其准确性甚至都高于GFT的预测结果。
但如果能够得到正确的运用,像谷歌这样的巨头掌握的数据体量的价值基本上是无法估量的。也就是说这些巨头们有责任把这些数据运用到最有利于公众利益的方面。
在2014年发表在《科学》杂志的一篇文章中,来自美国东北大学、休斯顿大学以及哈佛大学的研究人员解析了谷歌预测流感趋势失败的原因。该文章把GFT的预测表现欲建立在CDC(美国疾病预防控制中心)数据基础上的简单预测模型进行了对比,结果发现GFT的总体表现实际上更差。该文章还认为,GFT的模式可能能够在2-3年内保持比较稳定的预测准确率,但之后则容易出现较大的差错,需要进行重要的修改。
当然,本文的目的也并不是要埋没大数据的价值,目前的研究已经证明了大数据在建立疾病传播模型、突发事件的确认以及经济情况的预测等方面相比于传统的方式都显示出了独特的价值。虽然谷歌在流感预测方面的努力很有价值,但是他们在方法及数据方面极其不透明的情况都导致了无法很好的利用谷歌流感趋势(Google Flu Trends,GFT)的结果来进行任何的决策支持。
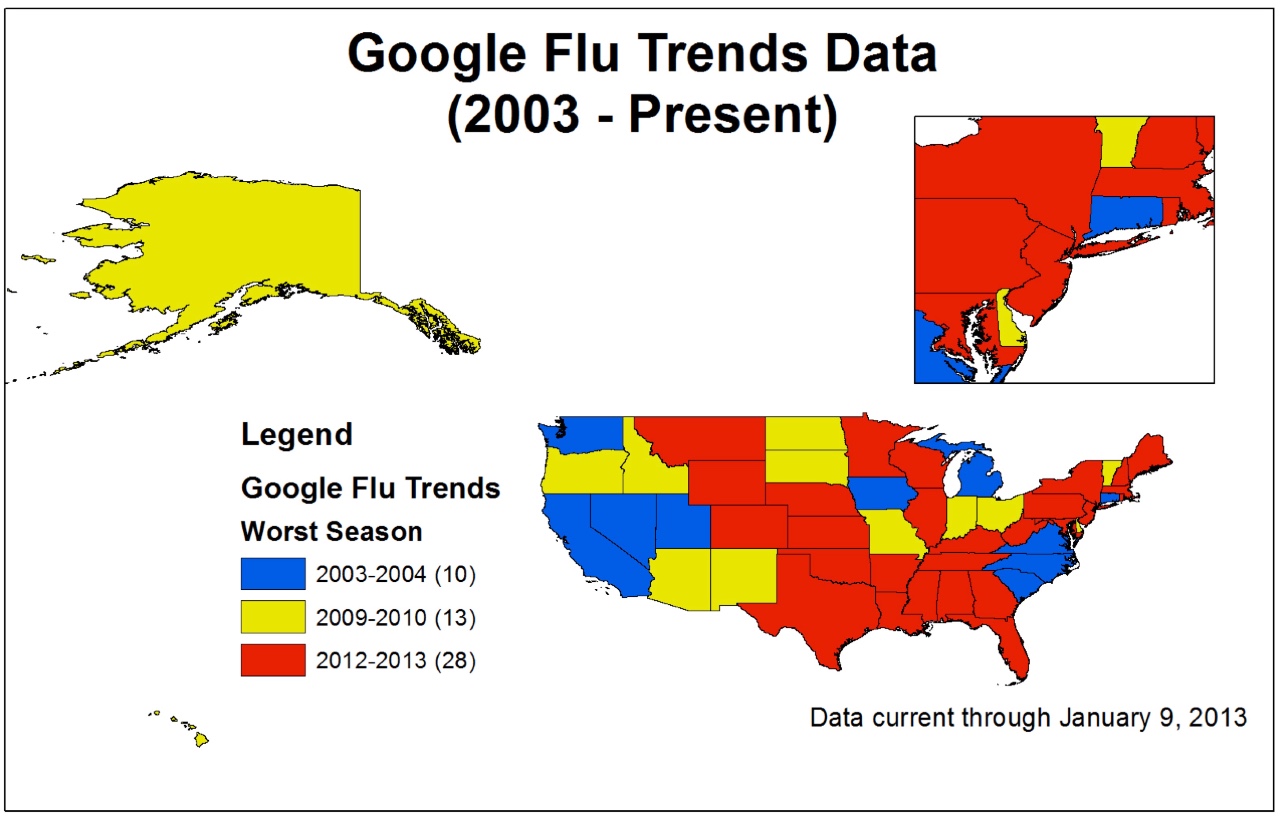
比如,谷歌的算法很容易受到与流感无关的周期性的词汇所影响,比如“高中篮球”等。每天都有上百万的与CDC的数据相关的搜索词汇,其中的许多搜索都会与流感趋势紧密相关,但其中也会存在着很多与流感相关的搜索实际上并不是又真正的流感病例引起或者与流感趋势有关。谷歌也没有把搜索时间产生的搜索行为的不同考虑在内。在引入GFT后,谷歌还引进了参照性的搜索特征以及大量与医疗健康相关的附件来帮助用户更快的找到他们所需要的信息。虽然这对用户来说非常有用,让他们可以更好的利用搜索引擎,也使得一些搜索词汇更为普遍,更利于GFT系统的追踪。
把大数据的功能运用于公共利益显然与谷歌本身是有很大不同的,毕竟谷歌需要更多的信任感,因为他需要经常对用户的数据进行“窥探”。用户的数据之所以存在是由于个人用户和公司之间双重的影响,而相关的法律术语则经常是十分模糊的(又有多少人会仔细的阅读相关的专业术语和法律条件呢?)。而交易真正能够达成的原因是用户获得了服务,而企业则获得了相关的数据。
而公共利益则是接下来才会被考虑的。而企业和消费者实际上都是广义的社会的一部分,而对这些大数据进行解读显然能够让我们大家都获得好处。正如谷歌CEO埃里克•施密特(Eric Schmidt)所说:“我们必须牢记的是科技一直都只是人类的一项工具。”而关键在于,我们,以及这些科技巨头们如何利用大数据来造福人类的。
谷歌在流感预测方面的尝试可能能够成为企业利用大数据造福社会的一个好的模式。谷歌已经把与流感相关的搜索数据开放给了CDC遗迹一些研究机构。关键的问题在于谷歌接下来是否会与这些研究机构一起来改进GFT。未来的版本也许可以更新数据追踪的方式以实现更精准的流感趋势预测,而数据流本身的价值则将会逐渐减退。
当然这只是其中的一种可能性,然而怎样建立跨行业的、跨政府、研究机构以及不同的利益关联者之间的大数据运用模型依然面临着很大的挑战。比如在埃博拉流行期间如何建立一种合理的数据共享模式,利用智能手机的数据来了解西非埃博拉疫情蔓延情况。(智能手机数据可能是目前最好的理解人类和埃博拉迁移的手段了)。企业们可能需要从公共利益的角度来思考如何在尊重个人隐私的基础上进行信息共享。
解决这一问题可能不仅仅是这一个办法,但已经有相关人员在波士顿建立了一个“大数据仓库”,方便大数据的拥有者们可以在完全安全的状态下将数据开放给研究者。联合国也建立了“全球脉搏行动”(Global Pulse initiative),以便于在全球的范围内建立协作数据存储库。一个位于瑞典的非盈利性组织Flowminder则专注于搜集智能手机的数据信息,以应对可能的灾难。但是这些都还只是细微的、初期的、碎片化的尝试。
现在的问题则是如何将这些尝试进一步的推进并形成体系,同时也要保护个人的隐私以及这些大数据“所有者”的利益。









